







")



")











")
If you own a website, you want to make sure that it is easily found and crawled by search engines like Google.
However, there may be certain parts of your website that you want to keep hidden from search engine crawlers, such as sensitive information or duplicate content.
This is where something called the “robots.txt” comes in.
Robots.txt is a small text file that sits on your website’s server and tells search engine crawlers which pages or files they are allowed to access.
It’s a powerful tool for website owners to control the crawling and indexing of their site’s content.
In this guide, we’ll provide a comprehensive introduction to robots.txt, including what it is, how it works, and best practices for using it effectively.
Whether you’re a seasoned webmaster or a beginner in the world of SEO, understanding robots.txt is essential for optimizing your website’s visibility and performance in search results.
What is robots.txt?

Robots.txt is a file that sits on a website’s server and instructs search engine crawlers which pages or files they are allowed to access.
This file is often located in the root directory of a website and contains a set of directives that inform search engine robots, also known as “bots,” about the content that should or should not be crawled or indexed.
A robots.txt file is essentially a communication tool between the website owner and the search engine crawler, telling the crawler which pages or sections of the site to ignore or prioritize.
For example, a website may have private pages or directories that should not be indexed or duplicate content that needs to be excluded from search results.
By using the robots.txt file, website owners can control how their website’s content is crawled, indexed, and displayed in search results.
It’s important to note that while robots.txt can help control which pages are crawled, it doesn’t guarantee that those pages won’t be indexed or displayed in search results.
Additionally, some search engines may not follow the instructions provided in robots.txt, so it’s best to use other techniques, such as meta tags, to ensure that sensitive or duplicate content is excluded from search results.
Why is Robots.txt important?

The importance of robots.txt for website owners lies in the fact that it provides a way to control how search engines crawl and index their website’s content. Here are some key reasons why website owners should pay attention to their robots.txt file:
- Improved crawl budget management: Search engines have a limited budget for crawling each website, so it’s important to prioritize which pages or sections of a site should be crawled first. By using robots.txt to specify which pages are off-limits, website owners can make sure that search engine crawlers are spending their budget on the most important pages.
- Protection of sensitive information: Some websites may have pages or directories that contain sensitive information, such as personal data or financial records. By using robots.txt to block search engine crawlers from accessing these pages, website owners can help protect the privacy and security of their users’ data.
- Avoidance of duplicate content penalties: Search engines penalize websites that have duplicate content, as it can be seen as spammy or manipulative. By using robots.txt to exclude duplicate pages, such as printer-friendly versions or archive pages, website owners can help ensure that their site isn’t penalized for having duplicate content.
- Improved SEO performance: By controlling how search engines crawl and index their website’s content, website owners can improve their website’s visibility and performance in search results. For example, by excluding low-value pages from search results, website owners can focus on promoting their most valuable content, which can help attract more traffic and leads to their site.
Overall, robots.txt is an important tool for website owners to manage how search engines crawl and index their website’s content, which can help improve their website’s visibility, privacy, and overall SEO performance.
History of Robots.txt
Robots.txt has a fascinating history that reflects the evolution of search engine technology and web development practices.
In the early days of the internet, search engines struggled to keep up with the rapidly expanding web, leading to the development of search engine crawlers and spiders that could automatically index web pages.
However, these crawlers faced challenges in navigating and interpreting websites, which led to the creation of the first robots.txt file in 1994.
Over the years, robots.txt has evolved into a standard protocol for website owners to communicate with search engine crawlers, allowing them to control which pages are crawled and indexed.
Today, robots.txt remains a critical tool for website owners and SEO professionals, as they seek to optimize their website’s visibility and performance in search results.
Robots.txt syntax and format
The syntax and format of robots.txt is a set of rules that website owners use to communicate with search engine crawlers about which pages on their website they want to be indexed or excluded from indexing.
The robots.txt file is a plain text file that is typically placed in the root directory of a website, and it contains a set of directives that specify the behaviour of search engine crawlers.
The most common directives include “User-agent,” which specifies which crawler the following directives apply to, “Disallow,” which specifies which pages or directories should not be crawled, and “Allow,” which specifies which pages or directories can be crawled.
The syntax also includes other directives, such as “Sitemap” and “Crawl-delay,” which provide additional information about the website’s structure and behaviour.
The format of the file includes guidelines for file naming, character encoding, line breaks, and comments. Properly following the syntax and format of robots.txt is essential for ensuring that search engine crawlers behave as intended on a website.
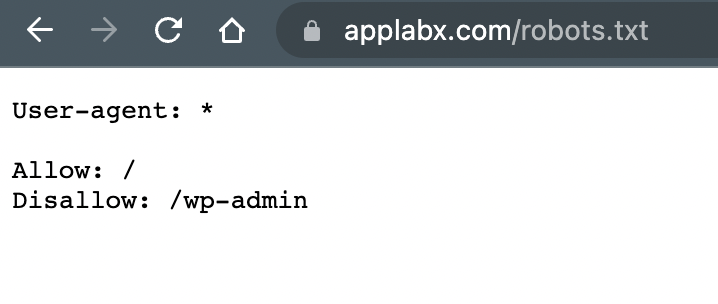
Below is an example of a robots.txt file on AppLabx.
How robots.txt differs from meta tags
While robots.txt and meta tags are both used to control how search engine crawlers interact with a website, they serve different purposes and operate at different levels of a website’s architecture.
Robots.txt is a file that is placed in the root directory of a website and communicates with search engine crawlers to specify which pages or directories should be indexed or excluded from indexing.
It works at the site-wide level and can be used to exclude entire sections of a website from being crawled.
On the other hand, meta tags are HTML tags that are placed on individual pages of a website and provide additional information about the page’s content to search engine crawlers.
They are used to provide metadata such as title, description, and keywords, which can help search engines better understand the page’s content and rank it accordingly.
While robots.txt controls the behaviour of search engine crawlers at a high level, meta tags provide more granular information about individual pages, helping to optimize them for search engines.
By using both robots.txt and meta tags effectively, website owners can ensure that their sites are optimized for search engines at both the site-wide and page levels.
How Robots.txt works?
How search engine robots crawl websites
Search engine robots, also known as crawlers or spiders, use sophisticated algorithms to crawl and index websites.
When a crawler visits a website, it begins by requesting the robots.txt file to determine which pages are allowed to be crawled.
Once it has obtained this information, the crawler starts by crawling the home page and then follows links to other pages on the site.
As the crawler visits each page, it extracts information such as text content, images, and metadata.
This information is then used to build an index of the website’s content, which is used to rank the website’s pages in search results.
Crawlers typically prioritize crawling high-quality content that is frequently updated and linked to by other reputable websites.
In addition to following links on a website, crawlers can also be directed to specific pages using XML sitemaps or URLs submitted through Google Search Console.
By understanding how search engine robots crawl websites, website owners can optimize their sites to improve their visibility and ranking in search results.
Role of robots.txt in controlling search engine crawlers
Robots.txt plays a critical role in controlling how search engine crawlers interact with a website.
By providing instructions to search engine robots on which pages should be crawled and indexed, website owners can ensure that their sites are properly optimized for search engines.
Robots.txt allows website owners to exclude certain pages or directories from being crawled, which can help prevent duplicate content issues, reduce server load, and protect sensitive information.
For example, if a website has a login page, it may want to exclude this page from being crawled to prevent user data from appearing in search results.
By using robots.txt effectively, website owners can also prevent search engines from indexing low-quality pages that could potentially harm their site’s search ranking.
However, it’s important to note that while robots.txt can instruct search engine robots which pages not to crawl, it does not guarantee that they won’t be indexed or appear in search results.
For this reason, it’s important to use other SEO techniques, such as meta tags and XML sitemaps, to optimize website content for search engines.
Common robots.txt directives and how they work
Robots.txt files use a series of directives to instruct search engine crawlers on how to crawl a website.
The most common directives are “User-agent,” which specifies the search engine crawler to which the following directives apply, and “Disallow,” which tells the crawler which pages or directories should not be crawled.
For example, the directive “User-agent: Googlebot” followed by “Disallow: /images” would instruct the Googlebot crawler not to crawl any pages or directories that begin with “/images.”
Similarly, the “Allow” directive specifies which pages or directories the search engine crawler is allowed to crawl.
Another important directive is “Sitemap,” which informs search engine crawlers of the location of the website’s XML sitemap file.
This helps search engines discover and index the website’s pages more efficiently.
Finally, the “Crawl-delay” directive can be used to specify the number of seconds that the crawler should wait between requests.
This can help reduce server load and prevent search engine crawlers from overloading a website’s resources.
By using these common robots.txt directives effectively, website owners can control how search engine crawlers interact with their websites and optimize their content for search engine rankings.
User-agent
In the context of robots.txt files, a “User-agent” refers to the specific search engine crawler that the following directives apply.
The User-agent line is used to specify the name of the search engine crawler or user agent that the directives below it apply.
For example, a User-agent line that reads “User-agent: Googlebot” would indicate that the following directives apply specifically to Google’s search engine crawler, while a User-agent line that reads “User-agent: *” would indicate that the following directives apply to all search engine crawlers.
By using User-agent directives in conjunction with other robots.txt directives, website owners can control how search engine crawlers interact with their websites and optimize their content for search engine rankings.
There are many different types of user agents on the web.
Top 10 web crawlers and bots
- GoogleBot
- Bingbot
- Slurp Bot
- DuckDuckBot
- Baiduspider
- Yandex Bot
- Sogou Spider
- Exabot
- Facebook external hit
- Applebot2
For example, to input instructions to target the GoogleBot, one can type:
User-agent: GooglebotOr if one wants to target Bingbot, then you can type:
User-agent: BingbotDisallow
In the context of robots.txt files, “Disallow” is a directive used to instruct search engine crawlers not to crawl specific pages or directories on a website.
When a search engine crawler visits a website, it will first check the robots.txt file to determine which pages it is allowed to crawl.
If a Disallow directive is included in the robots.txt file for a specific page or directory, the search engine crawler will not crawl or index that content.
For example, the directive “Disallow: /admin” would prevent search engine crawlers from accessing any pages or directories within the “/admin” directory on a website.
Disallow directives are commonly used to prevent search engines from indexing pages or directories that contain low-quality or sensitive content, or that are not intended for public consumption.
By using Disallow directives effectively in their robots.txt files, website owners can prevent certain pages from appearing in search engine results and improve the visibility and ranking of their site’s higher-quality content.
Blocking all web crawlers from all content
User-agent: * Disallow: /This will block all web crawlers such as GoogleBot, Bingbot, etc. from crawling your content, including the homepage.
Allowing all web crawlers access to all content
User-agent: * Disallow: By removing the “/”, it will tell all the web crawlers that there are no disallowed pages for the website so the web crawlers will be crawling all pages.
Blocking a specific web crawler from a specific folder
User-agent: Bingbot Disallow: /example-of-a-subfolder/This command will tell a specific web crawler, which in this case is the Bingbot, not to crawl a specific folder of the website
Blocking a specific web crawler from a specific web page
User-agent: Bingbot Disallow: /example-of-a-subfolder/blocked-page.htmlThis will tell a specific web crawler, which in this case is the Bingbot, not to crawl a specific webpage corresponding to the one input in the command.
Allow
In the context of robots.txt files, “Allow” is a directive used to instruct search engine crawlers which pages or directories they are allowed to crawl and index on a website.
This directive is used in conjunction with “Disallow” directives, which tell search engine crawlers which pages or directories they should not crawl.
For example, if a website owner wants to allow search engines to crawl a specific directory but not its subdirectories, they could use a “Disallow” directive to block the subdirectories, and an “Allow” directive to allow access to the parent directory.
Allow directives are used to override any previous Disallow directives and allow crawlers to access specific pages or directories that would otherwise be blocked.
By using “Allow” directives effectively in their robots.txt files, website owners can ensure that search engine crawlers are able to crawl and index all of their site’s important pages while still blocking low-quality or sensitive content.
Sitemap
In the context of robots.txt files, “Sitemap” is a directive used to inform search engine crawlers of the location of a website’s XML sitemap file.
An XML sitemap is a file that lists all of the pages on a website that the website owner wants search engines to crawl and index.
By including the location of the sitemap file in the robots.txt file, website owners can make it easier for search engines to discover and index all of their website’s pages.
The sitemap directive is written in the following format: “Sitemap: [URL of sitemap file].” For example, a sitemap directive that reads “Sitemap: https://www.example.com/sitemap.xml” would indicate that the website’s sitemap file is located at “https://www.example.com/sitemap.xml”.
By including a sitemap directive in their robots.txt file, website owners can ensure that search engines are able to crawl and index all of their important pages more efficiently, which can help improve their website’s visibility and ranking in search engine results.
Crawl-delay
In the context of robots.txt files, “Crawl-delay” is a directive used to specify the amount of time that a search engine crawler should wait between successive requests to a website.
The Crawl-delay directive is used to limit the rate at which search engine crawlers access a website in order to reduce the load on the server and prevent the crawler from overwhelming the site.
The Crawl-delay directive is written in the following format: “Crawl-delay: [number of seconds].” For example, a Crawl-delay directive that reads “Crawl-delay: 10” would instruct search engine crawlers to wait 10 seconds between each successive request to the website.
By using Crawl-delay directives effectively in their robots.txt files, website owners can prevent search engine crawlers from accessing their site too frequently and causing server overload, which can lead to slower page load times and potential penalties from search engines.
Best Practices for Using Robots.txt
- Common mistakes to avoid
- Recommendations for creating an effective robots.txt file
- Focus on Crawl Budget Optimisation
- Use robots.txt in conjunction with other SEO techniques
- Test your robots.txt file to ensure it works correctly
Common mistakes to avoid
There are several common mistakes that website owners can make when using robots.txt files.
These mistakes can prevent search engine crawlers from accessing important pages on a website, or can inadvertently allow access to pages that should be blocked. Some common mistakes to avoid when using robots.txt files include:
- Blocking access to important pages: Website owners should be careful not to block access to important pages on their site by using overly-restrictive Disallow directives in their robots.txt file. This can prevent search engine crawlers from indexing those pages and can negatively impact the website’s visibility in search engine results.
- Failing to update the file: Website owners should make sure to update their robots.txt file whenever changes are made to the website’s content or structure. Failure to do so can result in search engine crawlers being blocked from accessing important pages or being allowed access to pages that should be blocked.
- Using incorrect syntax: Robots.txt files must be written in a specific format and syntax in order for search engine crawlers to correctly interpret them. Website owners should ensure that their robots.txt file is properly formatted and free of syntax errors.
- Not including a sitemap: Website owners should include a Sitemap directive in their robots.txt file to inform search engine crawlers of the location of their website’s XML sitemap file. This can help ensure that all important pages on the website are indexed by search engines.
- Failing to test the file: Website owners should test their robots.txt file to ensure that search engine crawlers are able to correctly interpret it and that important pages are not being blocked. This can be done using various online testing tools or by manually checking the file using a web browser.
By avoiding these common mistakes and following best practices for using robots.txt files, website owners can ensure that search engine crawlers are able to effectively crawl and index their site’s content, which can lead to improved visibility and ranking in search engine results.
Recommendations for creating an effective robots.txt file
To create an effective robots.txt file, website owners should follow these recommendations:
- Use a robots.txt file: Create a robots.txt file in the root directory of your website to guide search engine crawlers on which pages to crawl and which ones to ignore.
- Follow the correct syntax: Ensure that the robots.txt file is written in the correct format and syntax, with one user-agent per line followed by one or more directives.
- Include a Sitemap directive: Include a Sitemap directive in the robots.txt file to tell search engine crawlers where to find the XML sitemap file for the website.
- Use Disallow and Allow directives wisely: Use Disallow directives carefully to block access to unimportant or duplicate pages, and use Allow directives to grant access to pages that might otherwise be blocked.
- Test the file: Test the robots.txt file using various online testing tools or manually check the file using a web browser to ensure that it is correctly written and is not blocking access to important pages.
- Regularly update the file: Regularly update the robots.txt file as changes are made to the website’s content or structure to ensure that search engine crawlers are able to access the website’s pages effectively.
By following these recommendations, website owners can create an effective robots.txt file that helps guide search engine crawlers on which pages to crawl and which ones to ignore, leading to improved visibility and ranking in search engine results.
Focus on Crawl Budget Optimisation
Crawl budget optimization refers to the process of making sure that search engine crawlers are efficiently crawling a website’s pages within the allocated crawl budget. The crawl budget is the number of pages that search engine crawlers can crawl on a website within a certain time period.
Focusing on crawl budget optimization involves taking steps to ensure that search engine crawlers are crawling the most important pages on a website, and not wasting time on pages that are less important.
This can involve implementing best practices for website architecture, such as minimizing duplicate content, ensuring that pages have unique and descriptive titles and meta descriptions, and using proper URL structure.
Additionally, website owners can use tools such as Google Search Console to monitor the crawl activity on their website and identify any crawl issues that need to be addressed. This can include fixing broken links, improving page load speed, and resolving any crawl errors that are identified.
By focusing on crawl budget optimization, website owners can help ensure that search engine crawlers are effectively crawling their website’s pages and that important content is being indexed, leading to improved visibility and ranking in search engine results.
Use robots.txt in conjunction with other SEO techniques
Robots.txt can be used in conjunction with other SEO techniques to improve the visibility and ranking of a website in search engine results. Here are some ways to use robots.txt in conjunction with other SEO techniques:
- Use robots.txt to block access to duplicate content: Duplicate content can harm a website’s search engine ranking. By using robots.txt to block access to duplicate content, website owners can ensure that search engine crawlers are focusing on the original content and not wasting the crawl budgets on duplicate pages.
- Use robots.txt to improve crawl budget optimization: As mentioned earlier, crawl budget optimization is an important SEO technique. By using robots.txt to guide search engine crawlers on which pages to crawl and which ones to ignore, website owners can ensure that the crawlers are focusing on the most important pages.
- Use robots.txt with sitemap.xml to improve indexing: The sitemap.xml file helps search engine crawlers to better understand a website’s structure and identify its most important pages. By including a link to the sitemap.xml file in the robots.txt file, website owners can help search engine crawlers to find and index the most important pages more efficiently.
- Use robots.txt with meta tags: Meta tags can help improve the visibility of a website in search engine results. By using robots.txt to guide search engine crawlers on which pages to crawl and which ones to ignore, website owners can ensure that the meta tags are applied to the most important pages, leading to better visibility and ranking in search engine results.
By using robots.txt in conjunction with other SEO techniques, website owners can improve the visibility and ranking of their website in search engine results and attract more traffic to their site.
Test your robots.txt file to ensure it works correctly
To test your robots.txt file to ensure it works correctly, you can follow these steps:
- Use a robots.txt testing tool: There are several online tools available that allow you to test your robots.txt file. One such tool is the Google Search Console. You can submit your robots.txt file to the tool and it will simulate how Googlebot would crawl your site based on your file.
- Check your server logs: Your server logs can give you valuable insights into how search engine crawlers are interacting with your site. By reviewing your server logs, you can see whether search engine crawlers are accessing the pages that you have allowed in your robots.txt file and whether they are being blocked from accessing the pages that you have disallowed.
- Use the “Fetch as Google” tool: This tool is also available in the Google Search Console. You can use it to fetch a URL as Googlebot and see whether the page is being blocked by your robots.txt file.
- Check your site’s search engine results: By checking your site’s search engine results, you can see whether the pages that you have allowed in your robots.txt file are being indexed by search engines and whether the pages that you have disallowed are not appearing in search engine results.
By testing your robots.txt file regularly, you can ensure that it is working correctly and that search engine crawlers are accessing the pages that you want them to access, leading to improved visibility and ranking in search engine results.
Conclusion
In conclusion, robots.txt is an essential tool for website owners who want to control how search engine crawlers access their sites.
By using robots.txt, website owners can guide search engine crawlers on which pages to crawl and which ones to ignore, ensuring that the crawlers are focusing on the most important pages.
With the right directives, website owners can also use robots.txt to block access to duplicate content, improve crawl budget optimization, and enhance the indexing of their site.
It is important to remember, however, that robots.txt is just one component of a comprehensive SEO strategy. By using robots.txt in conjunction with other SEO techniques, website owners can improve the visibility and ranking of their website in search engine results and attract more traffic to their site.
So, take the time to create an effective robots.txt file and keep it up to date to ensure that your website is optimized for search engine crawlers and is visible to your target audience.
For Powerful SEO and Digital Marketing Services, email us at [email protected] or whatapps us at +65 9800 2612.
AppLabx is a digital consultancy agency based in Singapore and in the Asia Pacific region. Since 2016, it has served more than hundreds of clients, spread across a diverse range of industries and sectors.
People also ask
1. How to ensure that the robots.txt file is properly configured to allow search engines to crawl and index all important pages of the website?
To ensure that the robots.txt file is properly configured to allow search engines to crawl and index all important pages of the website, follow these steps:
- Identify the important pages: First, identify the important pages on your website that you want search engines to crawl and index. This includes pages with valuable content, high-converting landing pages, and pages that receive a lot of traffic.
- Use the “Allow” directive: Use the “Allow” directive to specifically allow search engines to crawl and index the important pages of your site. Make sure that you have listed all of the URLs that you want to be crawled and indexed by search engines.
- Test your robots.txt file: Test your robots.txt file using the methods described earlier to ensure that it is working correctly and that search engine crawlers are able to access all of the important pages on your site.
- Submit a sitemap: Submit a sitemap of your site to search engines to ensure that all important pages are discovered and crawled. A sitemap is an XML file that lists all of the pages on your site that you want search engines to crawl and index.
- Monitor search engine results: Monitor search engine results regularly to ensure that all important pages on your site are being indexed and appearing in search results.
By following these steps, you can ensure that the robots.txt file is properly configured to allow search engines to crawl and index all important pages of your website. This can help improve your site’s visibility in search engine results and attract more traffic to your site.
2. How to perform a crawl analysis of the website to identify any pages that should not be blocked by robots.txt?
To perform a crawl analysis of your website to identify any pages that should not be blocked by robots.txt, follow these steps:
- Choose a web crawling tool: Choose a web crawling tool such as Screaming Frog, Ahrefs, or SEMrush to crawl your website. These tools will give you a comprehensive view of all pages on your site and how they are structured.
- Crawl your website: Enter your website’s URL into the web crawling tool and start the crawl. The tool will crawl your entire website and collect data on every page it finds.
- Analyze the crawl data: Once the crawl is complete, analyze the data to identify any pages that should not be blocked by robots.txt. Look for pages with valuable content, high-converting landing pages, and pages that receive a lot of traffic.
- Compare the data with the robots.txt file: Compare the data from the crawl with the robots.txt file to ensure that all important pages are not being blocked. If you find that important pages are being blocked, update the robots.txt file accordingly.
- Test the updated robots.txt file: Test the updated robots.txt file using the methods described earlier to ensure that it is working correctly and that search engine crawlers are able to access all of the important pages on your site.
By performing a crawl analysis of your website, you can identify any pages that should not be blocked by robots.txt and ensure that your site is properly optimized for search engine crawlers. This can help improve your site’s visibility in search engine results and attract more traffic to your site.
3. How to test the robots.txt file to ensure that it is properly blocking access to pages that should not be indexed by search engines while allowing access to all other pages?
To test the robots.txt file and ensure that it is properly blocking access to pages that should not be indexed by search engines, you can use the following tools:
- Google Search Console: Google Search Console is a free tool provided by Google that allows you to test your robots.txt file. The tool will show you which pages are being blocked by your robots.txt file and which pages are not.
- Robots.txt Tester: The Robots.txt Tester is a tool provided by Google Search Console that allows you to test your robots.txt file. The tool will show you any syntax errors in your file and will also show you which pages are being blocked by your robots.txt file.
- Screaming Frog SEO Spider: Screaming Frog SEO Spider is a popular web crawling tool that can be used to test your robots.txt file. The tool allows you to simulate a search engine crawler and will show you which pages are being blocked by your robots.txt file.
- Robots.txt Checker: Robots.txt Checker is a free online tool that allows you to test your robots.txt file. The tool will show you any syntax errors in your file and will also show you which pages are being blocked by your robots.txt file.
By using these tools to test your robots.txt file, you can ensure that it is properly blocking access to pages that should not be indexed by search engines. This can help improve your site’s visibility in search engine results and prevent search engines from indexing pages that may be harmful to your site’s performance.
4. How to ensure that any changes to the website’s structure or content are reflected in the robots.txt file to ensure that search engines can continue to crawl and index all important pages?
To ensure that any changes to the website’s structure or content are reflected in the robots.txt file, you should follow these steps:
- Regularly review your website: Keep an eye on your website’s structure and content to ensure that any new pages or changes to existing pages are properly reflected.
- Update your robots.txt file: If you make any changes to your website’s structure or content, update your robots.txt file to ensure that search engines can continue to crawl and index all important pages. For example, if you add a new section to your website, make sure that it is not blocked by the robots.txt file.
- Test your robots.txt file: After updating your robots.txt file, test it using the tools mentioned in the previous answer to ensure that it is properly blocking access to pages that should not be indexed by search engines.
- Monitor your website’s performance: Keep an eye on your website’s performance in search engine results to ensure that search engines are indexing all important pages. If you notice any issues, review your robots.txt file to ensure that it is not blocking access to important pages.
By following these steps, you can ensure that any changes to your website’s structure or content are properly reflected in the robots.txt file. This can help improve your site’s visibility in search engine results and ensure that search engines are able to crawl and index all important pages.
5. What other measures to take to ensure that search engine crawlers can properly understand and index the website’s content?
In addition to ensuring that the robots.txt file is properly configured, there are several other measures you can take to ensure that search engine crawlers can properly understand and index your website’s content:
- Use proper meta tags: Make sure that your website’s meta tags (such as the title tag, meta description, and header tags) accurately reflect the content of each page. This can help search engines understand the context and relevance of your content.
- Use sitemaps: A sitemap is a file that lists all of the pages on your website, which can help search engines find and crawl all of your content. Make sure that your sitemap is up to date and that it accurately reflects the structure of your website.
- Use on-page optimization techniques: Proper on-page optimization can help search engines understand the content of your pages and improve your site’s visibility in search engine results. This can include techniques such as using descriptive URLs, optimizing images and videos, and using internal linking to help search engines navigate your site.
- Monitor your website’s performance: Regularly monitor your website’s performance in search engine results to ensure that search engines are properly indexing all of your important pages. If you notice any issues, review your website’s content and structure to identify any potential issues.
By implementing these measures, you can help ensure that search engines are able to properly understand and index your website’s content, which can help improve your site’s visibility and performance in search engine results.
6. How often to review and update the robots.txt file to ensure that it remains properly configured as the website evolves and changes over time?
It is important to review and update the robots.txt file regularly to ensure that it remains properly configured as the website evolves and changes over time. How often you should review and update the file will depend on the frequency of changes to your website’s structure and content.
As a general rule, you should review your robots.txt file whenever you make significant changes to your website’s structure or content, such as adding or removing pages, changing the website’s URL structure, or updating your content management system.
Additionally, you should review your robots.txt file regularly (e.g. every few months) to ensure that it remains up to date and accurately reflects the current structure and content of your website.
If you use a content management system or web development platform, you may also want to review the robots.txt file whenever you update the system or install new plugins or extensions, as these changes can sometimes affect the file’s configuration.
Regularly reviewing and updating your robots.txt file can help ensure that search engine crawlers are able to properly crawl and index your website’s content, which can improve your site’s visibility and performance in search engine results.
7. Are there any potential risks or downsides to blocking certain pages or sections of the website with robots.txt? If so, how to mitigate these risks?
Yes, there are potential risks or downsides to blocking certain pages or sections of the website with robots.txt. The main risk is that it could result in decreased visibility and traffic for the blocked pages or sections, which could impact your overall search engine optimization (SEO) efforts. If search engine crawlers are unable to access important pages or sections of your website, these pages may not be indexed and may not appear in search engine results, which could result in a loss of traffic and potential customers.
To mitigate these risks, it is important to carefully consider which pages or sections of your website you want to block with robots.txt. You should only block pages or sections that are not important for search engine optimization or that contain sensitive or confidential information that should not be indexed by search engines.
In addition, you can use other SEO techniques, such as proper use of meta tags, sitemaps, and on-page optimization, to ensure that search engines are able to properly understand and index your website’s content, even if certain pages or sections are blocked with robots.txt.
Finally, it is important to regularly review and update your robots.txt file to ensure that it accurately reflects the current structure and content of your website, and to check for any unintended consequences or negative impacts on your site’s visibility and performance in search engine results.


 Image Sizes in 2024: The Ultimate Guide")


")
 how to crawl pages on their website.){kind=link}