







")



")











 and How Do They Work")
Key Takeaways
- Large Language Models (LLMs) are advanced AI systems built on transformer architecture and deep learning, trained on massive datasets to understand and generate human-like text.
- LLMs work by predicting the next word in a sequence using billions of parameters and self-attention mechanisms, enabling tasks like chat, summarisation, translation, and code generation.
- From enterprise automation to conversational AI, LLMs are transforming industries—while also presenting challenges such as bias, hallucinations, and governance concerns.
Understanding Large Language Models (LLMs) has become essential for anyone interested in artificial intelligence, machine learning, digital transformation, or the future of technology. Over the past few years, LLMs have rapidly evolved from niche research tools to mainstream AI powerhouses underpinning everything from conversational assistants to automated content generation and enterprise knowledge systems. At their core, LLMs are advanced neural networks trained on massive volumes of text data so they can understand, process, and generate human-like language. These models excel at detecting patterns and relationships in language, enabling them to perform a wide range of tasks that previously required bespoke systems or extensive human programming.

In essence, a large language model functions as a predictive engine.
It has learned, through exposure to billions or even trillions of words, how language flows and which sequences of words are most likely to follow a given input.
This allows the model not only to complete sentences and answer questions but also to generate original text, translate languages, summarize documents, and even support application-specific workflows like code generation or sentiment analysis.
LLMs are built on complex deep learning architectures, most notably the transformer, which enables them to consider the context of language at scale.
This means they can weigh relationships between words in long passages of text and generate responses that are contextually relevant and coherent.
This capability has propelled them far beyond traditional language models that relied on simpler statistical methods.
As these technologies continue to improve and expand across industries, they are reshaping how businesses interact with information, how software assistants assist with tasks, and even how people communicate with machines.
Yet, despite their impressive performance, understanding how LLMs work and what drives their ability to generate human-like language remains a topic of active exploration, innovation, and debate in the fields of AI research and practical deployment.
But, before we venture further, we like to share who we are and what we do.
About AppLabx
From developing a solid marketing plan to creating compelling content, optimizing for search engines, leveraging social media, and utilizing paid advertising, AppLabx offers a comprehensive suite of digital marketing services designed to drive growth and profitability for your business.
At AppLabx, we understand that no two businesses are alike. That’s why we take a personalized approach to every project, working closely with our clients to understand their unique needs and goals, and developing customized strategies to help them achieve success.
If you need a digital consultation, then send in an inquiry here.
Or, send an email to [email protected] to get started.
What Are Large Language Models (LLMs) and How Do They Work
- What Are Large Language Models (LLMs)
- The Core Technology Behind LLMs
- How LLMs Work in Practice
- Real-World Applications of LLMs
- Benefits of Using LLMs
- Challenges & Limitations
- Examples of Popular LLMs
- The Future of LLM Technology
1. What Are Large Language Models (LLMs)
Large Language Models (LLMs) are one of the most transformative advancements in artificial intelligence today. They are sophisticated AI systems trained to understand, process, and generate human language by learning from vast amounts of text data. In practical terms, LLMs power tools that can write essays, answer questions, translate languages, summarise documents, support coding tasks, and much more.
Core Definition of an LLM
At their essence, Large Language Models are a specialised type of deep learning model that excels at natural language processing (NLP) tasks by estimating the likelihood of word sequences and generating coherent text. They consist of neural networks with billions to trillions of parameters, enabling them to capture complex patterns in language.
The term “large” traditionally refers to models with very high parameter counts compared to earlier language models, which enables richer text generation and deeper contextual understanding.
How LLMs Work — In Simple Terms
LLMs are trained using self-supervised learning on massive text corpora. During training, the model learns to predict the next token (word piece or character) in a sentence, internalising grammar, knowledge, and contextual patterns. This ability to make high-accuracy predictions across diverse language tasks is what sets LLMs apart from traditional NLP models.
Key concepts include:
- Tokens — Text is broken into smaller meaningful units used by the model.
- Parameters — Adjustable numeric values learned during training that represent language understanding.
- Transformers — The dominant architecture behind modern LLMs, enabling efficient handling of long-range dependencies in text.
LLM Characteristics and Capabilities
Large Language Models exhibit a set of defining characteristics that make them powerful for a wide range of applications.
Massive Scale and Parameter Counts
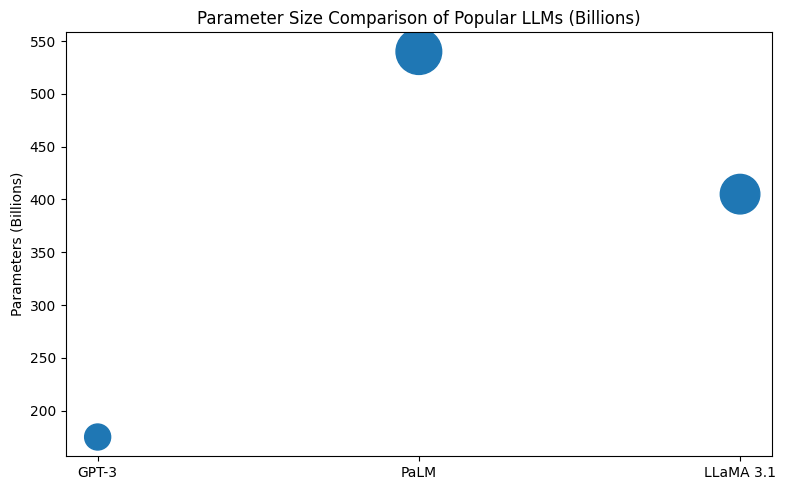
LLMs are typically defined by very large parameter counts. For example:
| Model | Estimated Parameter Count | Notes |
|---|---|---|
| GPT-3 | 175 billion | Became widely known after release in 2020. |
| GPT-4 (rumoured) | ~1.76 trillion | Estimated by independent sources, exact details not officially disclosed. |
| PaLM 2 | 540 billion | Represents a major non-OpenAI competitor. |
These high parameter counts allow LLMs to learn nuanced linguistic patterns and generalise across many language tasks.
Transformer Architecture
Most modern LLMs are built using the transformer architecture, introduced in 2017 and now the backbone of language reasoning models due to its ability to process entire sequences of text in parallel using self-attention mechanisms. This allows the model to analyse contextual relationships across large text spans — vital for understanding context and generating coherent responses.
Training Data and Diversity
LLMs are pre-trained on massive corpora that can span:
- Internet-scraped data such as web pages, books, and articles
- Licensed data sources
- Curated datasets spanning multiple languages and domains
The size and diversity of training data directly impact the model’s language comprehension and output quality.
Examples of Large Language Models
LLMs are operationalised in many well-known AI systems. Some of the most prominent include:
| LLM Name | Organisation | Typical Use Cases |
|---|---|---|
| GPT-4 | OpenAI | Conversational AI, content generation, coding assistance. |
| PaLM 2 | Multilingual translation, text generation. | |
| Google Gemini | Multimodal LLM orchestrating text, image, and other data types. | |
| LLaMA family | Meta Platforms | Open-source LLMs for research and development. |
These examples illustrate both proprietary and open ecosystems in LLM development, highlighting the variety in scale, capability, and accessibility across vendors.
Capabilities Demonstrated by LLMs
Large Language Models support a wide range of language tasks:
- Text Generation — Producing coherent paragraphs, stories, and dialogue.
- Summarisation — Condensing documents while preserving meaning.
- Translation — Converting text across different languages.
- Question Answering — Providing answers based on prompts or knowledge-inferred patterns.
- Content Assistance — Supporting code generation, drafting emails, creating educational content.
Why They’re Called “Large” Language Models
The word “large” refers to multiple factors:
- Parameter size — Much larger than traditional language models.
- Training data volume — Trained on datasets orders of magnitude larger than prior systems.
- Capability diversity — Able to generalise across many tasks without bespoke training.
This scale is a cornerstone of why LLMs are effective as general-purpose AI language engines.
Summary Table: LLM Fundamentals
| Dimension | Description |
|---|---|
| Definition | Deep learning models trained to process and generate human language. |
| Architecture | Transformer-based neural networks. |
| Scale | Billions to trillions of parameters. |
| Data | Trained on internet-scale text, licensed datasets, multilingual corpora. |
| Capabilities | Text generation, translation, summarisation, reasoning support. |
| Examples | GPT-4, PaLM 2, Google Gemini, Meta LLaMA. |
By understanding what LLMs are and the foundational principles that underpin their design and performance, readers gain insight into why they have triggered a wave of innovation across industries, from software development and education to customer support and beyond.
2. The Core Technology Behind LLMs
Understanding the foundational technologies that power large language models (LLMs) is essential for appreciating how they have transformed modern artificial intelligence. These technologies—deep learning, neural networks, and the transformer architecture—are the engines behind LLMs’ ability to generate fluent, contextually relevant human language across a wide range of tasks.
Deep Learning and Neural Networks
Foundational Concept
At the heart of every LLM lies deep learning, a branch of machine learning that uses artificial neural networks to learn complex patterns from large datasets. Neural networks mimic the structure and function of the human brain, consisting of layers of interconnected nodes (neurons) that transform input data into meaningful outputs.
Neural Network Structure
Neural networks in LLMs typically consist of:
- Input Layer – Accepts processed data (tokens) representing text.
- Hidden Layers – Multiple layers of neurons that extract and transform features from the text.
- Output Layer – Produces the final prediction, such as the next word in a sentence.
These networks are categorised as deep when they contain many layers, allowing them to capture increasingly abstract language features such as syntax, semantics, and contextual dependencies.
Transformer Architecture
The most pivotal breakthrough in LLM development was the introduction of the transformer architecture in 2017, formalised in the seminal paper “Attention Is All You Need.” This architecture replaced older approaches that relied on recurrent or convolutional models.
Why Transformers Are Essential
Transformers support parallel processing of text, allow models to handle long-range relationships in language, and scale effectively with large datasets—capabilities that earlier architectures lacked. This efficiency is the backbone of modern LLMs including systems like GPT, PaLM, and Claude.
Self-Attention Mechanism
Definition
The transformer architecture’s core innovation is self-attention, which enables the model to determine the relevance of each word relative to others in a sequence. In technical terms, self-attention computes attention scores that quantify how much influence other tokens have when interpreting a given token.
How It Works
- Each token is projected into three vectors: Query (Q), Key (K), and Value (V).
- Attention scores are calculated by matching Q against K vectors, assigning a weight to each token’s influence.
- These weighted values (V) are combined to form context-aware representations.
This mechanism allows LLMs to understand context even across long sentences, questions, or entire paragraphs, enabling nuanced language interpretation and generation.
Multi-Head Attention and Positional Encoding
Transformers improve on basic self-attention with multi-head attention. Instead of a single attention computation, the model runs multiple attention mechanisms (heads) in parallel. Each head learns different relationships within the data, such as grammar, semantics, or long-distance dependencies.
Because transformers process all tokens simultaneously, they use positional encoding to retain information about word order—an element critical for understanding sentence structure.
Tokenization: Breaking Text into Machine-Readable Units
Before any neural model can process human language, raw text must be broken down into tokens. A token can represent:
- A word
- A subword fragment
- A character
Advanced tokenisation strategies such as Byte Pair Encoding (BPE) or SentencePiece help models efficiently represent language with a compact vocabulary.
Tokenisation allows the model to work with high-dimensional numeric representations rather than raw text, forming the first step in LLM data ingestion.
Training: Learning from Vast Data at Scale
LLMs are trained using self-supervised learning on massive datasets scraped from the web, books, articles, and other text sources. They predict the likelihood of sequences, learning language structure without labelled training examples.
This training strategy allows LLMs to internalise syntax, semantic patterns, and even general knowledge encoded in the training data. Larger models with more parameters and more training data exhibit stronger performance and broader generalisation capabilities.
Example Transformer-Based LLM Architectures
| Model Family | Architecture Type | Parameters (Approximate) | Primary Role |
|---|---|---|---|
| GPT (OpenAI) | Autoregressive Transformer | 175B and higher | Text generation & conversation |
| PaLM (Google AI) | Decoder-Only Transformer | 540B | Multilingual analysis & reasoning |
| LLaMA Series (Meta) | Decoder-Only Transformer | 8B – 405B | Flexible research and open-source models |
These models exemplify how transformer design scales to billions of parameters, enabling sophisticated language tasks like summarisation, translation, and reasoning.
Transformers vs Older Architectures
| Aspect | Recurrent/Convolutional Models | Transformer Models |
|---|---|---|
| Parallelism | Limited | Full parallel token processing |
| Long-Context Handling | Weak | Strong (via self-attention) |
| Training Scalability | Harder | Efficient with large data and compute |
| Typical Use Today | Historical | Dominant |
Transformers’ ability to weigh all tokens against each other makes them far superior for large-scale language modelling compared to earlier sequence models.
Summary Matrix: Core LLM Technologies
| Technology | Purpose | Key Contribution |
|---|---|---|
| Neural Networks | Predictive computation | Learns patterns in language |
| Transformer Architecture | Language contextualisation | Self-attention across long sequences |
| Self-Attention | Context weighting | Enables understanding of word relationships |
| Tokenization | Text preprocessing | Converts raw text to numeric tokens |
| Training on Big Data | Knowledge acquisition | Enables generalisation across NLP tasks |
This matrix captures how the core technologies work together to support LLM capabilities at scale.
In combination, these technological advancements—massive neural networks, the transformer architecture with self-attention, and intelligent token processing—form the backbone of modern large language models, enabling them to perform a wide range of NLP tasks with unprecedented sophistication.
3. How LLMs Work in Practice
Large Language Models (LLMs) are built using advanced training methods and deployed in real-world systems that generate, interpret, and apply text-based data. In practical applications, they go beyond theoretical architecture and become interactive engines powering tools such as chatbots, summarisation systems, translators, code assistants, and domain-specialised AI agents. Their operation involves concrete stages—from tokenisation and inference to optimization, deployment, and task-specific refinement.
Prompt to Output: The Inference Lifecycle
LLM inference refers to the active use of a trained model to produce meaningful outputs given a prompt or query. This is where the model’s training is put into action.
Tokenisation and Preprocessing
- Input text is tokenised into smaller units (words or subword tokens) that the model can process numerically.
- Tokens are transformed into embeddings—numerical vector representations that capture semantic and syntactic features.
- Embeddings feed into transformer layers to generate context-aware representations.
Autoregressive Generation
- Most mainstream LLMs (e.g., GPT-style models) generate text autoregressively, predicting one token at a time based on previous context.
- Each step evaluates the likelihood of the next token across the vocabulary, selecting the token with the highest probability or sampling according to defined strategies like temperature or top-k sampling.
Attention-Based Contextualisation
- The transformer architecture’s self-attention mechanism enables the model to assign different relevance weights to tokens across the input.
- This mechanism ensures that important contextual cues—such as key nouns or question phrases—have a stronger influence on the generated response.
Generation Continues Until Stopping Criteria
- The model continues generating tokens until a predefined stopping point (maximum length) or a special token signaling the end of generation.
Practical Example: From Prompt to Sentence
Consider the task of summarising a long document. An LLM processes the input as follows:
| Stage | Operation | Result |
|---|---|---|
| Prompt intake | Document text tokenised | Numeric representation |
| Contextualisation | Self-attention across tokens | Semantic understanding |
| Prediction | Next-token probabilities computed | Best token selected |
| Output | Sequence of tokens combined | Coherent summary |
This workflow allows LLMs to adapt to numerous NLP tasks—summarisation, translation, question answering, and more—with the same core inference process.
Execution Strategies and Output Control
LLMs expose several techniques to tailor output behaviour:
Temperature and Randomness Tuning
- Temperature controls how random or deterministic the text generation is. Lower values make outputs more predictable; higher values add creativity.
Top-k and Top-p Sampling
- Filters the set of possible next tokens to the most likely candidates, balancing diversity and coherence.
- Carefully crafted prompts can implicitly fine-tune context without retraining. For example, inserting “Respond in a professional tone” steers output style.
Deployment and Serving Models
Once inference logic is established, practical applications require systems to serve models efficiently:
Inference Servers
- Model deployment often uses specialised inference servers that load models, coordinate hardware (GPUs/TPUs), and handle application requests.
- These servers may implement batching, caching, and streaming to optimise latency and throughput.
Scaling Considerations
- As workloads grow, horizontal scaling (more servers) and vertical scaling (more powerful GPUs) help maintain performance.
- Advanced frameworks like vLLM and TensorRT-LLM are designed to maximise GPU utilisation and reduce response time.
Optimization Techniques for Real-World Efficiency
Efficient real-world systems often employ several optimisation strategies beyond basic inference:
| Optimization Strategy | Purpose | Impact |
|---|---|---|
| Batching | Groups multiple requests | Better GPU utilisation, higher throughput |
| KV Cache Management | Reuses computation | Faster handling of long context inputs |
| Quantisation (e.g., INT8) | Reduces numerical precision | Lower memory needs and compute cost |
| Distributed Inference | Parallel model execution | Scales for large or high-traffic systems |
Each technique balances speed, cost, and model precision, enabling deployment at scale for consumer apps, enterprise systems, and APIs.
Application Patterns in Practice
LLMs are embedded in diverse operational systems:
Conversational AI and Chatbots
- Real-time response generation based on user dialogue, often with persistence of context across sessions to deliver coherent interactions.
Content Generation Tools
- Applications such as document drafting, social media post creation, or automated email replies rely on the model’s generative capabilities without manual rewriting.
Language Translation and Summarisation
- LLMs can interpret complex text inputs and produce concise summaries or translate between languages by capturing semantic meaning.
Code Assistance and Reasoning Enhancements
- Tools can interpret natural language requirements and convert them into executable code. Advanced prompting strategies such as chain-of-thought or program-of-thought can guide reasoning over multi-step problems.
Deployment in Business Systems
In enterprise settings, LLMs are integrated into:
Customer Support Automation
- Real-time query response systems that reduce human workload and improve service responsiveness.
Knowledge Retrieval and RAG (Retrieval-Augmented Generation)
- Combines LLM inference with external databases to deliver more accurate information tailored to dynamic datasets.
Domain-Specific Fine-Tuning
- Instead of generic models, organisations fine-tune models on specialised corpora like legal text or medical records to improve relevance and precision.
Performance and Cost Considerations
Practical LLM systems must balance performance with cost:
Compute Demand
- LLMs with tens or hundreds of billions of parameters require significant GPU resources for both training and inference. Efficient architecture and optimisation are crucial to keep latency acceptable and costs manageable.
Context Window Limits
- Each model has a context window—the maximum number of tokens it can process at once. Newer LLMs support increasingly larger windows, enabling tasks like full-document summarisation or long dialogue maintenance.
Summary Matrix: LLM Practical Workflow
| Phase | Core Activity | Practical Output |
|---|---|---|
| Preprocessing | Tokenise and embed input | Numeric representations |
| Inference | Autoregressive token generation | Text output |
| Output Control | Temperature & sampling | Tailored responses |
| Deployment | Inference server & scaling | Real-world applications |
| Optimisation | Batching, caching, quantisation | Faster, cheaper performance |
In practice, LLMs transform raw textual prompts into meaningful, contextually relevant outputs through a sequence of computational and engineering stages. From tokenisation and inference to hardware optimisation and fine-tuning, these systems bridge the gap between state-of-the-art research and real-world utility across communication, automation, and decision-support applications.
4. Real-World Applications of LLMs
Large Language Models (LLMs) have moved beyond research labs and pilot projects to become core technologies in many industries, transforming workflows, enhancing productivity, and generating measurable business value. Their ability to understand and generate natural language, analyse data, and interact conversationally has enabled applications ranging from customer service automation to domain-specific analysis and decision support. Adoption statistics and use patterns illustrate how LLMs are reshaping work and technology. For example, 67% of organisations now use generative AI tools powered by LLMs in workflows, and 75% of workers have employed these tools in daily tasks — demonstrating substantial integration into modern business operations.
Conversational AI and Customer Interaction
LLMs power advanced chatbots, virtual assistants, and customer support systems capable of handling a wide range of user queries and tasks with natural, human-like responses. These systems enrich customer experience by enabling:
- Automated responses to customer inquiries across channels (web, mobile, social platforms)
- Context-aware help that can follow a customer’s history or previous questions
- Continuous support without the limitations of traditional rule-based chatbots
These LLM-driven systems are increasingly used in customer experience platforms to personalise interaction and reduce response times.
Examples of Conversational AI Applications Include:
| Application Type | Typical Tasks | Value Delivered |
|---|---|---|
| Virtual Support Agents | Answer FAQs, handle tickets | Lower support cost, faster resolution |
| Internal Helpdesk Bots | Employee policy queries, IT troubleshooting | Internal efficiency gains |
| Voice-Enabled Assistants | Conversational interface for devices | Enhanced accessibility |
Content Generation and Creative Automation
LLMs are widely used for generating text content across formats, from articles and marketing copy to creative storytelling and scriptwriting. Their generative capabilities are underpinned by extensive language pattern recognition, enabling fluent and contextually relevant content production.
Many professionals now use LLMs for research, creative writing, and communication tasks, with surveys showing over 50% of users employing LLMs for research and information gathering, 47% for creative content, and 45% for emails and communication.
Key Content Generation Use Cases:
| Use Case | Description | Business Impact |
|---|---|---|
| Blog and Article Writing | Automated drafts or outlines | Faster content production |
| Social Media Content | Customised posts and captions | Brand visibility and engagement |
| Email and Communication Templates | Professional email drafts | Saves time for knowledge workers |
Document Processing and Knowledge Extraction
LLMs excel at analysing unstructured text, summarising long documents, extracting key insights, and categorising information. These capabilities support:
- Automated summarisation of reports and meetings
- Extraction of key entities, dates, or topics from legal, medical, or technical documents
- Semantic search and query-based knowledge retrieval systems
By driving systems that interpret and summarise text, organisations can reduce manual effort and accelerate decision-making processes.
Enterprise Productivity and Operational Support
LLMs are widely embedded across enterprise functions, enabling task automation, internal process optimisation, and decision support.
Adoption and Productivity Impact
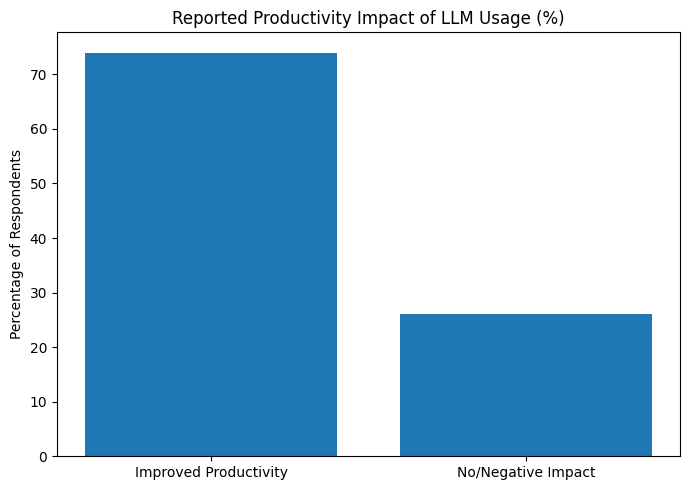
Industry data shows that LLMs significantly improve productivity at work. In a survey of technology professionals, 74% reported improved productivity through LLM use, with many noting measurable gains — including increased output when using LLMs versus declines when they were unavailable.
Operational Impact Across Functions:
| Function | LLM-Powered Application | Outcome |
|---|---|---|
| HR and Recruiting | Job description analysis, candidate screening | Faster hiring workflows |
| Sales & CRM | Automated lead qualification, follow-up drafts | Shorter sales cycles |
| Finance & Accounting | Report generation, financial summarisation | Reduced analysis time |
Industry-Specific Deployments
LLMs are applied across diverse sectors, each with unique use cases tailored to domain challenges:
Healthcare
- Clinical documentation summarisation
- Intelligent triage systems
- Patient information assistance
Finance
- Automated risk reporting and summarisation
- Customer service automation for banking queries
- Compliance checklists and regulatory summarisation
Retail & E-Commerce
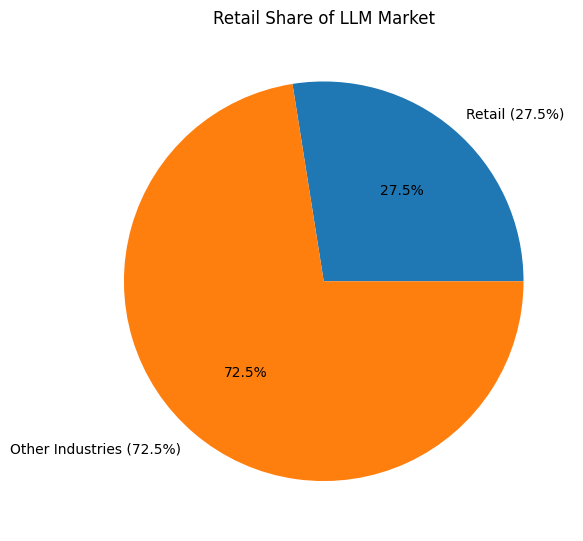
Retail leads the global LLM market with a share over 27.5%, where models analyse customer data, customise recommendations, and support real-time digital support.
Manufacturing & Industrial Systems
LLMs can optimise internal operational workflows and interpret technical documentation, enabling automated planning and error detection.
Logistics
Practical deployment examples include warehousing systems enhanced by LLM interfaces for complex queries across multiple languages.
Domain Knowledge Management and Search Enhancement
Beyond simple generation, LLMs are integrated with external knowledge repositories to boost reliability and accuracy. One emerging pattern is Retrieval-Augmented Generation (RAG), which merges LLM reasoning with direct access to structured databases and company documents. This approach enhances factual accuracy and domain relevance for query responses, particularly in knowledge management and enterprise support systems.
Deployment Scenarios with RAG:
- Legal document search with direct references
- Policy & compliance knowledge retrieval
- Internal enterprise Q&A portals
Programming Assistance and Technical Workflows
LLMs facilitate code generation, debugging support, and developer productivity enhancements. Tools like coding assistants integrate LLMs into development environments, enabling:
- Code snippet suggestion and explanation
- API usage guidance based on natural language instructions
- Automated testing and documentation support
These applications have reshaped software development workflows by reducing routine tasks and enabling developers to focus on higher-level problem solving.
Ethical, Research, and Social Use Cases
LLMs have also been adopted for societal and research purposes, such as analysing large datasets for academic insights or aiding in the drafting of international communication. Research into LLM-assisted writing shows that by late 2024 a significant portion of corporate press releases and public organisation communications involved LLM-generated text.
Non-Commercial Use Cases:
| Domain | Example Application | Value |
|---|---|---|
| Academic Research | Pattern analysis across large text corpora | Faster insight generation |
| Public Communications | Automated drafting and translation | Broader outreach |
| Public Sector Automation | Policy summarisation, public FAQs | Improved citizen engagement |
Summary Matrix: LLM Application Domains
| Domain Category | Representative Use Cases | Tangible Impact |
|---|---|---|
| Customer Interaction | AI chatbots, virtual assistants | Reduced support cost, improved experience |
| Content Generation | Automated writing and ideation | Greater output, creative assistance |
| Enterprise Productivity | Document processing, knowledge extraction | Speed, accuracy, time savings |
| Industry Solutions | Healthcare, finance, retail | Workflow transformation |
| Technical Support | Code assistance, debugging | Developer efficiency |
| Research & Public Use | Large data analysis, communication | Scalable insight extraction |
LLMs in practice are not confined to a single role—they are integrated across business functions, technical workflows, and industry solutions, delivering real, measurable improvements in efficiency, decision quality, and automation. Their wide adoption across organisations and continued growth in applications demonstrate their central role as a foundational technology in the modern digital landscape.
5. Benefits of Using LLMs
Large Language Models (LLMs) are among the most impactful innovations in artificial intelligence over the past decade. Organisations across industries have rapidly adopted LLMs to enhance productivity, automate workflows, improve decision-making, and unlock new avenues for innovation. These benefits arise from the ability of LLMs to interpret, generate, and contextualise human language at scale—transforming how businesses and individuals interact with data, customers, and internal systems.
Enhanced Productivity and Workflow Automation
Automating Repetitive Tasks
LLMs excel at automating repetitive and time-consuming language tasks. Whether it’s drafting emails, generating product descriptions, composing reports, or creating marketing content, LLMs reduce the manual workload for employees. For example, marketing teams can use LLMs to produce draft content quickly, allowing human writers to focus on refinement and strategy.
Accelerating Decision-Making with Data Insights
Rather than relying on manual data interpretation, LLMs can summarise complex information, extract key insights from large text datasets, and surface trends through natural language queries. This accelerates decision-making and allows departments such as sales, finance, and operations to react faster to changing conditions.
Productivity Gains Across Roles
| Role Category | Typical Productivity Benefit | Example |
|---|---|---|
| Marketing | Faster content generation | Draft blog posts and social content |
| Customer Support | Reduced response times | AI chatbots handle FAQs |
| Data Analysis | Rapid summarisation | Summarise survey results |
| HR & Recruiting | Screening automation | Candidate profile summaries |
These workflow enhancements make it possible to complete tasks faster and with fewer resources compared with traditional manual processes.
Cost Reduction and Operational Efficiency
Lower Operating Expenses
LLMs can help organisations reduce operational costs by:
- Reducing labour required for routine language tasks
- Minimising external vendor dependencies for translation or content creation
- Streamlining internal report and documentation processes
Many companies discover cost savings by automating functions that previously required large teams of staff. For example, AI-driven customer service solutions reduce the need for large call centre staffing while still providing personalised assistance.
Improved Resource Allocation
With LLMs handling operational tasks, organisations can reallocate human resources to higher-value activities such as strategy, innovation, and customer engagement. This rebalancing improves overall business agility and competitiveness.
Better Customer Experience and Engagement
24/7 Support with Natural Language Responses
LLM-powered chatbots and virtual assistants can provide round-the-clock support. These systems can answer common customer questions, resolve issues quickly, and escalate complex cases to human agents when necessary. Because responses are generated using natural, coherent language, customers experience more intuitive interactions.
Personalised Interactions
LLMs can tailor responses based on customer data and historical context, leading to more personalised experiences. For instance, e-commerce platforms utilise LLMs to offer product recommendations, translate customer feedback into actionable insights, or customise promotional messaging.
Customer Experience Outcomes
| Customer Experience Factor | LLM Contribution | Result |
|---|---|---|
| Response Time | Instant replies | Higher satisfaction |
| Consistency | Uniform tone and accuracy | Stronger brand trust |
| Personalisation | Contextual recommendations | Better engagement |
Improved customer experiences often translate into higher loyalty, increased upsell opportunities, and stronger brand reputations.
Smarter Data Analysis and Decision Support
Turning Unstructured Data Into Actionable Insights
One of the most powerful benefits of LLMs is their ability to understand unstructured text data—such as customer reviews, chat logs, market research reports, and internal documentation—and convert it into structured insights. By summarising key findings and extracting relevant information, LLMs help organisations make data-driven decisions more effectively.
Real-Time Query and Semantic Search
LLMs empower users to ask natural language queries against large datasets or internal knowledge bases and receive relevant, coherent responses. This reduces reliance on technical tools or specialised analysts for data retrieval.
Innovation Enablement and Competitive Edge
Accelerating Digital Transformation
LLMs accelerate digital transformation by enabling organisations to experiment with AI-driven services, build intelligent products, and differentiate offerings. Businesses that integrate LLMs into customer engagement channels, internal workflows, or analytics platforms often see gains in efficiency and innovation capacity.
Supporting New Business Models
LLMs enable new revenue streams and products such as AI-assisted writing tools, personalised learning platforms, intelligent document summarisation services, and automated consultation agents. By embedding AI into core products, companies can unlock capabilities that traditional systems cannot replicate.
Multilingual and Globalisation Support
Cross-Language Capabilities
Training on multilingual datasets allows many LLMs to process and generate text in multiple languages. This capability supports global businesses by:
- Translating content quickly
- Helping multinational support teams provide localized service
- Enabling global marketing efforts with culturally-relevant outputs
These functionalities make LLMs indispensable for organisations operating across geographical boundaries.
Matrix: Summary of LLM Benefits
| Benefit Category | Core Advantage | Typical Impact |
|---|---|---|
| Productivity | Automation & speed | Faster workflows |
| Cost Efficiency | Operational savings | Lower expenses |
| Customer Experience | Personalisation | Higher satisfaction |
| Data Insights | Advanced analysis | Better decisions |
| Innovation | New services | Competitive advantage |
| Global Scale | Multilingual support | Wider market reach |
This matrix encapsulates how LLMs generate value across strategic and operational dimensions.
Evidence from Industry and Economic Studies
Independent research highlights the broad economic impact of LLM adoption. According to McKinsey & Company, AI technologies—including LLMs and related automation tools—could contribute trillions of dollars in global economic value by improving productivity and supporting new business capabilities. Investments in LLM integration are rising as companies seek to unlock strategic advantages in an increasingly competitive environment.
Conclusion of Benefits Section
Large Language Models deliver multifaceted benefits that extend far beyond simple automation. By enhancing productivity, enabling smarter data analysis, reducing operational costs, improving customer experiences, supporting innovation, and facilitating global operations, LLMs are redefining core business processes and technological capabilities. As organisations continue adopting and refining LLM use cases, these benefits will deepen, supporting stronger performance and strategic growth in the years ahead.
6. Challenges & Limitations
Large Language Models (LLMs) have revolutionised natural language processing and AI applications, but they still face significant challenges and limitations. These limitations impact reliability, fairness, interpretability, computational efficiency, and safe deployment in real-world scenarios. Understanding these constraints is essential for responsible use, especially in high-stakes domains such as healthcare, legal analysis, finance, and autonomous systems.
Hallucinations and Inaccuracies
Definition and Impact
Hallucination refers to instances where LLMs produce text that appears fluent and plausible but is factually incorrect or fabricated. This fundamental issue persists across even advanced models and remains a key trust concern for users. Researchers note that hallucinations can arise from statistical approximation behaviours rather than structured reasoning and are inherent to how models are trained and evaluated.
Real-World Consequences
Hallucinations can lead to material errors in summaries of scientific research, misinformation across outputs, and erroneous decision support. One study showed that hallucinated references occurred in up to 22% of ChatGPT outputs and up to 26% for another leading model, underscoring the practical significance of this limitation.
Hallucination Matrix
| Hallucination Type | Description | Example Outcome |
|---|---|---|
| Factual Falsehood | Fabricated details presented as true | Incorrect dates, events, or claims |
| Misleading Synthesis | Mixing unrelated facts | Erroneous policy or scientific summaries |
| Unsupported Assertions | Claims without evidence | Misleading decision recommendations |
Bias, Fairness, and Ethical Risks
Algorithmic and Social Bias
LLMs reflect patterns in their training data, which often includes historical and societal biases. These biases can result in outputs that amplify stereotypes or unfair representations of people based on gender, ethnicity, language group, or nationality.
For example, research has documented cases where models assign occupational roles based on gender norms found in training texts. Cultural or language biases also emerge when English-dominant data skew responses toward Western perspectives.
Fairness Risks Across Domains
| Bias Category | Source | Potential Outcome |
|---|---|---|
| Gender | Training data stereotypes | Misrepresentation of roles |
| Cultural | English-centric corpora | Misaligned cultural context |
| Demographic | Uneven data coverage | False projections about groups |
Computational and Context Constraints
Limits in Token Processing and Memory
LLMs operate within a fixed “context window” — a maximum number of tokens they can process at once. This restricts their ability to handle very long documents in a single interaction.
When users supply multi-page texts, models may truncate information or lose coherence across extended content segments. This constraint impacts tasks requiring deep document understanding, such as legal review or long-form summarisation.
Computational Demands
Training and running LLMs requires extensive compute resources and memory, making deployment expensive and energy-intensive, particularly for large-scale applications.
Knowledge Update and Real-Time Learning
Static Knowledge Bases
Most LLMs are trained on datasets representing a snapshot in time, and models generally lack real-time learning or automatic knowledge updates. As a result, they cannot inherently access current events or integrate newly published information unless explicitly retrained or connected to external knowledge systems.
Knowledge Staleness
This limitation means LLM outputs may be outdated or inaccurate for topics involving recent developments, new research findings, or evolving industry standards.
Challenges with Reasoning and Domain Expertise
Shallow Understanding of Complex Logic
LLMs excel at pattern recognition but struggle with tasks requiring deep reasoning, problem decomposition, or logical calculation. For example, researchers found that performance declines significantly on complex mathematical reasoning and logical queries as problem complexity grows.
Lack of Domain-Specific Expertise
Although LLMs produce generalised outputs, they may lack precise domain knowledge necessary for specialised fields such as medical diagnostics or legal interpretation, where accuracy requires subject-expert reasoning and contextual nuance.
Interpretability and Trust
Opaque Decision Processes
LLMs are often described as “black boxes” because the reasoning behind generated outputs is not directly traceable to human-understandable logic. This lack of transparency complicates debugging, accountability, and regulatory compliance.
Trust and Reliability Concerns
Without clear interpretability, users may struggle to verify the basis for model outputs, leading to misplaced trust in incorrect or harmful responses.
Security and Misuse Risks
Vulnerabilities in Generated Content
LLMs can be used to generate disinformation, deepfakes, and other harmful content at scale. Open-source models without adequate safeguards present risks when deployed without monitoring or governance. One broad cybersecurity study observed widespread potential misuse of open-source LLM deployments for malicious activities such as phishing, hate speech, and fraud.
Training Poisoning Threats
Research indicates that LLM training data can be compromised by a small number of malicious documents, potentially “poisoning” the model’s behaviour and output integrity.
Ethical and Social Implications
Privacy and Data Protection
LLMs trained on large corpora scraped from public sources raise questions about data ownership, consent, and privacy. Sensitive personal information might be inadvertently reproduced in outputs if not properly filtered or protected.
Societal Impact and Misapplication
The broad use of LLMs in public discourse and decision support can shape opinions and actions, which requires careful ethical consideration to avoid unintended societal harm.
Comprehensive Challenge Matrix
| Challenge Category | Key Constraint | Domain Impact |
|---|---|---|
| Hallucinations | Factual errors in outputs | Misleading decisions |
| Bias & Fairness | Data-driven skew | Inequitable outcomes |
| Computational | Token limits & cost | Scalability issues |
| Knowledge Static | Outdated information | Poor current insight |
| Reasoning | Limited deep logic | Complex task failure |
| Interpretability | Opaque processes | Trust & accountability |
| Security Misuse | Vulnerability to abuse | Harmful content generation |
| Ethical | Privacy & social risks | User & societal harm |
Despite rapid advances, these challenges highlight the limitations inherent in current LLM technology and underscore the importance of human oversight, robust evaluation frameworks, and ongoing research into mitigation strategies. Addressing these constraints will be central to trustworthy, ethical, and high-impact LLM deployment across industries.
7. Examples of Popular LLMs
Large Language Models (LLMs) are central to modern AI applications, with a wide array of influential models developed by leading technology companies and open-source communities. These models vary in size, capabilities, domain focus, and licensing terms, providing options for different use cases such as conversational AI, coding assistance, enterprise workflows, multimodal processing, and open-source research. Below is a detailed look at prominent LLM examples shaping the current landscape of generative AI.
Flagship Proprietary Models from Major AI Providers
OpenAI’s GPT Series
The Generative Pre-trained Transformer (GPT) family from OpenAI is among the most recognised line of LLMs, powering many commercial AI services.
- GPT-5 – OpenAI’s flagship model launched in 2025 with extensive reasoning and multimodal capabilities, significantly outperforming prior versions across benchmarks. It supports extremely large context windows (e.g., hundreds of thousands of tokens) and excels across text, code, and multimodal inputs.
- GPT-4o / GPT-4.5 – Multimodal models capable of processing text, images, and other inputs, serving as the backbone for platforms like ChatGPT and integrated tools such as GitHub Copilot.
These models are often accessed via API and enable commercial deployments across enterprise software, productivity suites, and AI assistants.
Anthropic’s Claude Family
Anthropic has developed a line of LLMs focused on safety, scalability, and business-oriented reasoning:
- Claude 3.7 Sonnet – A high-capability model with large context windows (~200,000 tokens) suited for creative writing, coding, and extended dialog.
- Claude Opus 4.6 – Enterprise-focused iteration with extremely long context support (up to 1,000,000 tokens in beta), enabling complex knowledge work such as codebases and legal or financial document analysis.
Anthropic’s models are widely used in business environments where nuanced understanding and detailed responses are required.
Google DeepMind’s Gemini & Gemma Models
Google has progressed from research models to commercially competitive LLMs:
- Gemini Series – Sophisticated AI models that prioritise long-context understanding, creative task performance, and multimodal processing. Gemini models are positioned as general-purpose AI engines across Google services and APIs.
- Gemma Family – LLMs designed for multilingual and domain-specific tasks, with versions tailored for medical analysis (MedGemma) and on-device execution. Gemma models have collectively amassed over 150 million downloads, indicating widespread developer adoption.
Gemini and Gemma represent Google’s strategy of versatile, multimodal AI with broad applicability.
Meta’s LLaMA Series and Open-Source Advancements
Meta Platforms has consistently pushed open-source LLM development with its LLaMA family:
- LLaMA (Large Language Model Meta AI) – The original models offered several parameter scales (e.g., 7B, 13B, 33B, 65B) targeting the research community.
- LLaMA 3.1 (405B) – A large-scale open-source model that achieved leading performance on reasoning benchmarks such as ARC and GSM-8K, with expanded token context support.
In 2025, Meta introduced LLaMA 4 Scout and Maverick, which further expanded capabilities with mixture-of-experts architectures and impressive performance, all released under open-source licenses.
Other Notable LLMs Across the Ecosystem
xAI’s Grok Models
- Grok-4 – The latest from Elon Musk’s xAI, designed with real-time awareness and extensive reasoning improvements, often integrated with platforms like X for conversational tasks.
Open-Source and Community Models
The open-source community has produced a variety of capable LLMs suitable for research, on-premise deployment, and specialised tasks:
- Mistral Large 2 – An open-source model with 123 billion parameters, offering multilingual support and strong coding performance.
- Falcon Series – A set of open-source LLMs widely used for research and commercial experimentation.
- DeepSeek R1 – A model combining large parameter counts with efficient inference suited for demanding reasoning applications.
- Qwen Series (Alibaba) – Includes models like Qwen-2.5-Max and Qwen-1.5, designed for multilingual support and open-source accessibility.
These models broaden access to advanced AI capabilities beyond proprietary platforms.
Comparison Matrix: Popular LLMs by Category
| Model Family | Developer / Organisation | Typical Strengths | Licensing |
|---|---|---|---|
| GPT-5 / GPT-4 | OpenAI | General intelligence, multimodality, coding | Proprietary |
| Claude Series | Anthropic | Enterprise reasoning, safety | Proprietary |
| Gemini / Gemma | Google DeepMind | Multimodal tasks, language understanding | Proprietary with APIs |
| LLaMA Series | Meta Platforms | Research flexibility, open-source | Open Source |
| Grok | xAI | Real-time inference, integration | Proprietary |
| Mistral | Mistral AI | Open-source performance | Open Source |
| Qwen | Alibaba | Multilingual and open access | Open Source |
Representative Use Case Examples
Enterprise Productivity
- GPT and Claude models are widely embedded in customer support automation, document summarisation pipelines, and virtual assistant workflows.
Coding and Technical Workflows
- GPT variants (e.g., in GitHub Copilot) and Grok have specific tuning for coding assistance, offering enhanced IDE integration and debugging support.
Research and Custom Deployment
- Open-source models like LLaMA and Mistral can be fine-tuned or deployed on local infrastructure for custom research or privacy-sensitive applications.
Understanding the range of popular LLMs highlights the diversity of current AI technology — from proprietary models dominating commercial offerings to community-driven open-source systems fostering research, custom deployments, and global innovation. As the field evolves, new models and specialised variants continue to emerge, expanding what is possible with large language models in business, research, and consumer applications.
8. The Future of LLM Technology
The evolution of Large Language Models (LLMs) is rapidly progressing from experimental research tools to foundational components of intelligent systems that impact business operations, software development, digital services, and national technology strategy. As 2026 unfolds, several key trends and developments are emerging that are likely to shape the future trajectory of LLM technology — including advancements in reasoning, deployment strategies, specialised models, optimisation techniques, and integration with broader AI ecosystems. These future directions point toward deeper contextual understanding, greater efficiency, and more industry-specific solutions.
Advances in Reasoning, Memory, and Context
Deeper Contextual Understanding
Future LLMs are expected to better process longer and more complex contexts that go far beyond the current generation of models. Researchers are actively exploring mechanisms — such as hierarchical memory systems and enhanced internal reasoning pathways — that enable models to retain and reason over extended interactions without losing coherence or performance. These enhancements are key to tasks such as extended legal or scientific document analysis and complex dialog systems.
Hybrid Reasoning Approaches
Models that integrate retrieval-augmented generation (RAG) with traditional generative capabilities are becoming a standard architectural choice for knowledge-accurate systems. By pairing live retrieval from external knowledge bases with generative reasoning, these hybrid systems can significantly reduce factual errors and provide up-to-date information beyond the model’s training data.
Reinforcement-Learning Enhancements
In research contexts, combining reinforcement learning (RL) techniques with LLM training is expected to improve instruction following, adaptability, and reasoning performance by guiding models toward more aligned and task-effective behavior. Reinforcement learning research helps LLMs refine output quality through reward-based feedback loops that simulate more human-like decision processes.
Multimodal and Cross-Domain Integration
Multimodal Capabilities
LLMs are evolving to handle not just text but text combined with images, audio, and other data types. This transition to multimodal intelligence enables richer interactions such as context-aware image descriptions, audio-assisted understanding, and integrated multi-medium responses. Real-world examples already include systems that combine text and visual inputs with reasoning capabilities — a trend expected to expand across domains like robotics, autonomous systems, and real-time analytics.
Cross-Domain Foundation Models
Emerging research suggests LLM-style models can extend into specialised infrastructure roles beyond language — such as large wireless foundation models designed for communications systems in next-generation networks (e.g., 6G). These models use similar foundational architectures but are tuned for domain-specific signal processing and automation tasks.
Optimisation, Efficiency, and Cost Management
Efficient LLMs for Business Use
As LLMs become integral to enterprise workflows, efficiency, latency reduction, and cost optimisation will be key priorities. Market research indicates that organisations are shifting from proof-of-concept to operational deployment, where optimised inference pipelines and intelligent model distillation reduce computational costs and improve performance. Trends such as Industry-specific LLMs — smaller but fine-tuned models tailored to vertical tasks — are growing in adoption because they can deliver specialised performance with lower resource requirements.
Agentic AI and Autonomous Processes
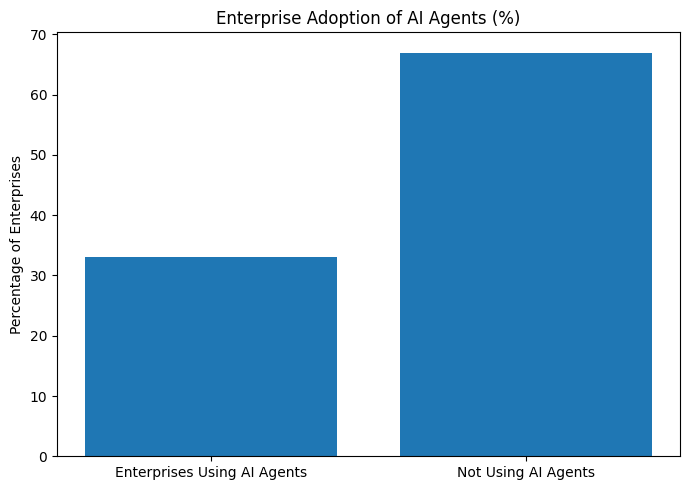
The growth of AI agents — systems that operate with autonomy and can perform task sequences without direct human prompts — is accelerating. Some forecasts project that over one-third of enterprises will incorporate AI agents into daily workflows, driving automation in support, HR, sales, and operations. This reflects broader interest in making LLM-driven systems proactive and independent, rather than reactive tools.
Scaling Laws and Hardware Research
Beyond software optimisation, there is active research into hardware design specifically for LLM inference and training. As models grow in size and contextual demands increase, specialised chips and infrastructure designed to handle LLM workloads efficiently will reduce energy consumption and improve speed. Advances in this area are likely to shape training paradigms and lower barriers to entry for smaller organisations.
Emerging Market Growth and Strategic Diversification
Projected Market Expansion
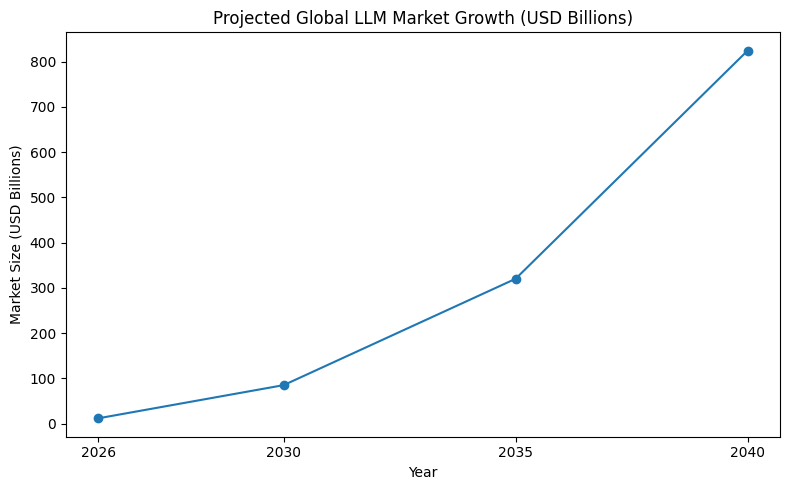
Market forecasts for the LLM sector point to explosive growth over the next decade. Industry analysts project that the global LLM market, valued around USD 11.63 billion in 2026, could grow to USD 823.93 billion by 2040 at a compound annual growth rate (CAGR) of 35.57%. This reflects expanding investment and integration of LLM technology across diverse industry verticals — including digital services, healthcare, finance, and IoT-connected systems.
Open-Source and National AI Initiatives
Open-source LLM development continues to flourish, driven by community demand for transparency, customisation, and cost-effective solutions. In parallel, several national strategies aim to build sovereign AI models — region-specific systems trained on culturally-relevant data to reduce dependence on foreign technologies. These initiatives support local language understanding, data privacy, and domain alignment.
Ethics, Safety, and Governance Considerations
Responsible AI and Regulation
As LLM technologies become embedded in critical applications, AI governance, safety protocols, and ethical standards will increasingly influence future development. Regulators and research communities are focusing on strategies to mitigate bias, ensure transparency, and align outputs with human values. Improved frameworks for auditability and compliance will be essential in domains such as healthcare, legal services, and finance.
Model Alignment and Bias Mitigation
Efforts to improve alignment — ensuring that LLM outputs follow ethical guidelines and societal norms — are set to expand with continual human feedback loops, better training datasets, and integrated verification systems. These strategies aim to reduce harmful or biased outputs while preserving model performance.
Matrix: Future LLM Trends and Impacts
| Future Trend | Technical Focus | Practical Impact |
|---|---|---|
| Extended Context Reasoning | Memory & long-interaction handling | Better performance on complex tasks |
| Multimodal Intelligence | Text, image, audio fusion | Broader input/response capabilities |
| Hybrid Architectures | Retrieval + generative models | Reduced hallucinations, up-to-date knowledge |
| Optimised LLMs | Cost & compute reduction | Wider enterprise deployment |
| AI Agents | Autonomous task execution | Higher automation in workflows |
| Hardware Innovations | Efficient LLM inference & training | Lower energy & faster performance |
| Market Growth | Sector expansion & specialised models | Increased investment and supply diversity |
| Ethical Governance | Bias & safety frameworks | Trustworthy AI systems |
Anticipated Long-Term Developments
Towards Artificial General Intelligence (AGI)
While current LLMs are powerful in specialised tasks, research into dynamic learning architectures — such as models that adapt internal representations in real time — seeks to push AI closer to generalised intelligence. Early prototype systems inspired by human-brain adaptability suggest possibilities for future models that continuously learn from interaction rather than remain static after training.
Integration with Broader AI Ecosystems
LLMs are expected to serve as central nodes within broader artificial intelligence ecosystems that include robotics, decision-assist tools, simulation engines, and real-time analytics platforms. These integrated AI systems could transform sectors such as autonomous vehicles, smart infrastructure, and digital assistants in daily life.
The future of LLM technology will be defined by advancements in reasoning depth, multimodal intelligence, efficiency optimisation, and strategic adoption across domains. Market growth, coupled with ethical governance and hardware innovation, will shape how these models evolve from toolkits for text generation to core components of intelligent systems that drive business transformation and societal progress.
Conclusion
In this comprehensive exploration, we’ve taken a deep dive into what Large Language Models (LLMs) are, how they operate, and why they have become one of the most influential technologies in artificial intelligence today. As advanced AI systems designed to understand, generate, and interact with human language, LLMs represent a major leap forward from traditional rule-based or statistical language tools. They leverage deep learning architectures—especially transformer models—to capture context, patterns, and semantic relationships within text, enabling a broad range of applications from conversational AI to summarisation and code generation. ([turn0search1]; [turn0search2]; [turn0search5])
At their core, LLMs are pre-trained on massive datasets containing billions or even trillions of words drawn from books, articles, websites, and other text sources. Through self-supervised learning, they internalise language structures and statistical associations between words and phrases, allowing them to generate coherent text that aligns with user prompts. This training process forms the basis of their ability to perform natural language processing tasks with minimal additional task-specific training. ([turn0search1]; [turn0search2])
A critical innovation behind LLMs is the transformer architecture, which enables models to process entire sequences of text through self-attention mechanisms. This approach allows LLMs to weigh the relevance of different parts of a text in context, producing more nuanced, contextually-aware outputs than earlier neural network models. Modern LLMs may contain billions to trillions of parameters, each acting as a learned representation that contributes to the model’s understanding of language. ([turn0search5])
The practical impact of LLMs extends across industries and workflows. They power AI chatbots, virtual assistants, automated content generation tools, semantic search engines, and interactive knowledge systems. These capabilities have transformed customer support, enterprise productivity tools, educational aids, and creative applications by enabling natural language interactions with machines. They also serve as foundational models for specialised systems that fine-tune the general capabilities of LLMs to domain-specific tasks. ([turn0search1]; [turn0search2])
Despite their transformative power, LLMs are not without limitations. They can generate inaccurate or misleading outputs—often referred to as hallucinations—because they produce the most statistically likely continuation of text rather than grounded factual answers in real time. They may also reflect biases present in their training data and require careful governance when deployed in contexts requiring high levels of accuracy and fairness. Human oversight and verification remain essential, especially in high-stakes domains such as research summarisation, legal analysis, and medical guidance. ([turn0search5]; [turn0search13])
The evolution of LLM technology continues rapidly, with ongoing research focused on extending model capabilities, improving factual accuracy, enhancing efficiency, and addressing ethical concerns. Future advancements include better memory and reasoning mechanisms, tighter integration of retrieval-based knowledge sources, multimodal processing that spans text and other data types, and more efficient architectures designed for real-world deployment at scale.
In summary, LLMs are powerful AI systems that enable machines to understand and generate human language at unprecedented scale and complexity. Their deep learning foundations, transformer-based design, and vast parameter counts empower applications that were previously impractical or impossible. While they offer significant benefits and transformative potential, responsible and informed use remains crucial as LLMs continue to shape how humans interact with technology in the years ahead. By grasping both their capabilities and limitations, organisations and individuals can harness LLMs to drive innovation while mitigating risk—a balance that defines the future of human-AI collaboration.
If you are looking for a top-class digital marketer, then book a free consultation slot here.
If you find this article useful, why not share it with your friends and business partners, and also leave a nice comment below?
We, at the AppLabx Research Team, strive to bring the latest and most meaningful data, guides, and statistics to your doorstep.
To get access to top-quality guides, click over to the AppLabx Blog.
People also ask
What is a Large Language Model (LLM)?
A Large Language Model is an AI system trained on massive text datasets to understand and generate human-like language using deep learning and transformer architecture.
How do Large Language Models work?
LLMs work by predicting the next word in a sentence based on context, using billions of parameters and self-attention mechanisms to generate coherent responses.
Why are LLMs called “large”?
They are called large because they contain billions or trillions of parameters and are trained on enormous datasets compared to earlier language models.
What is transformer architecture in LLMs?
Transformer architecture is a neural network design that uses self-attention to process entire text sequences at once, improving context understanding and scalability.
What is self-attention in Large Language Models?
Self-attention allows an LLM to weigh the importance of different words in a sentence to understand context and relationships between them.
What are examples of popular Large Language Models?
Popular LLMs include GPT models, Claude, Gemini, LLaMA, and Mistral, which power chatbots, search tools, and AI assistants.
What is the difference between LLMs and traditional NLP models?
Traditional NLP models rely on rules or smaller datasets, while LLMs use deep learning and large-scale data to perform multiple language tasks more accurately.
What tasks can Large Language Models perform?
LLMs can generate text, summarize documents, translate languages, answer questions, assist with coding, and power conversational AI systems.
Are LLMs the same as chatbots?
No, LLMs are the underlying AI models, while chatbots are applications that use LLMs to deliver conversational experiences.
How are Large Language Models trained?
LLMs are trained using self-supervised learning on vast text datasets, learning to predict missing or next words in sentences.
What are parameters in an LLM?
Parameters are adjustable numerical values learned during training that help the model understand language patterns and context.
Do Large Language Models understand meaning like humans?
LLMs simulate understanding by identifying patterns in data, but they do not possess human consciousness or true comprehension.
What is tokenization in LLMs?
Tokenization is the process of breaking text into smaller units called tokens so the model can process and analyze them numerically.
Can LLMs generate original content?
Yes, LLMs can create original text based on learned patterns, though the output is generated from statistical predictions rather than true creativity.
What industries use Large Language Models?
Industries such as healthcare, finance, education, marketing, retail, and software development use LLMs for automation and analysis.
What are the benefits of using LLMs?
LLMs improve productivity, automate repetitive tasks, enhance customer support, and provide scalable content and data analysis solutions.
What are the limitations of Large Language Models?
Limitations include hallucinations, bias, outdated knowledge, high computational costs, and limited explainability.
What is hallucination in LLMs?
Hallucination occurs when an LLM generates information that sounds plausible but is factually incorrect or fabricated.
How do LLMs handle multiple languages?
Multilingual LLMs are trained on diverse datasets containing different languages, allowing them to translate and generate text across languages.
Are Large Language Models safe to use?
LLMs can be safe when properly governed, but they require monitoring to prevent misinformation, bias, or misuse.
What is fine-tuning in Large Language Models?
Fine-tuning is the process of training a pre-trained LLM on specialized data to improve performance in specific domains.
How do LLMs improve search engines?
LLMs enhance search engines by understanding user intent, delivering contextual answers, and powering semantic search capabilities.
What is Retrieval-Augmented Generation (RAG)?
RAG combines LLMs with external data sources to provide more accurate and up-to-date responses.
Do Large Language Models replace human jobs?
LLMs automate certain tasks but are more commonly used to augment human productivity rather than fully replace professionals.
How accurate are Large Language Models?
Accuracy depends on training data, model size, and use case; while often highly capable, LLMs can still produce errors.
What is a context window in an LLM?
A context window is the maximum amount of text an LLM can process at once to generate responses.
How do LLMs impact content creation?
LLMs streamline content creation by generating drafts, outlines, and summaries, reducing time and effort for writers and marketers.
What hardware is required to run Large Language Models?
Training large models requires powerful GPUs or specialized AI hardware, while smaller versions can run on cloud or optimized systems.
What is the future of Large Language Models?
The future includes better reasoning, multimodal capabilities, improved efficiency, and stronger governance frameworks.
Why are Large Language Models important for AI development?
LLMs represent a major breakthrough in artificial intelligence by enabling scalable, human-like language understanding across applications.
Sources
Wikipedia
IBM
Google Developers
Google Cloud
OpenAI
arXiv
Reuters
NVIDIA Developer Blog
BentoML
Hugging Face
TechTarget
Coursera
Evidently AI

 Image Sizes in 2024: The Ultimate Guide")

 are, how they work, and how they power AI tools like chatbots, search, and content generation.){kind=link}